Using Database Replicas in Rails with Octopus Gem
Everyone waits until the ideal moment to take life-changing decisions. For most people, the beginning of a new year is the best time for choosing bold approaches or goals. As a company handling an increase in resolutions in health and fitness, we at Freeletics are challenged with the task of providing the best possible experience for our users, while catering for an increase in usage.
The combination of a spike in interest and a wide coverage for our advertising campaigns meant that we expected a growth in traffic on our backend. This forced us to scale up and organise the backend to handle the increase in traffic. Here’s some background and insight into what we did.
Over the past two years, we have gradually split our monolithic backend into different services, while maintaining one big service to handle most of the Bodyweight app logic. This Bodyweight service has only 1 r3.2xlarge AWS RDS Postgres database, which handles all the writes and reads.
We use Kubernetes to host our backend services, structuring them like this:
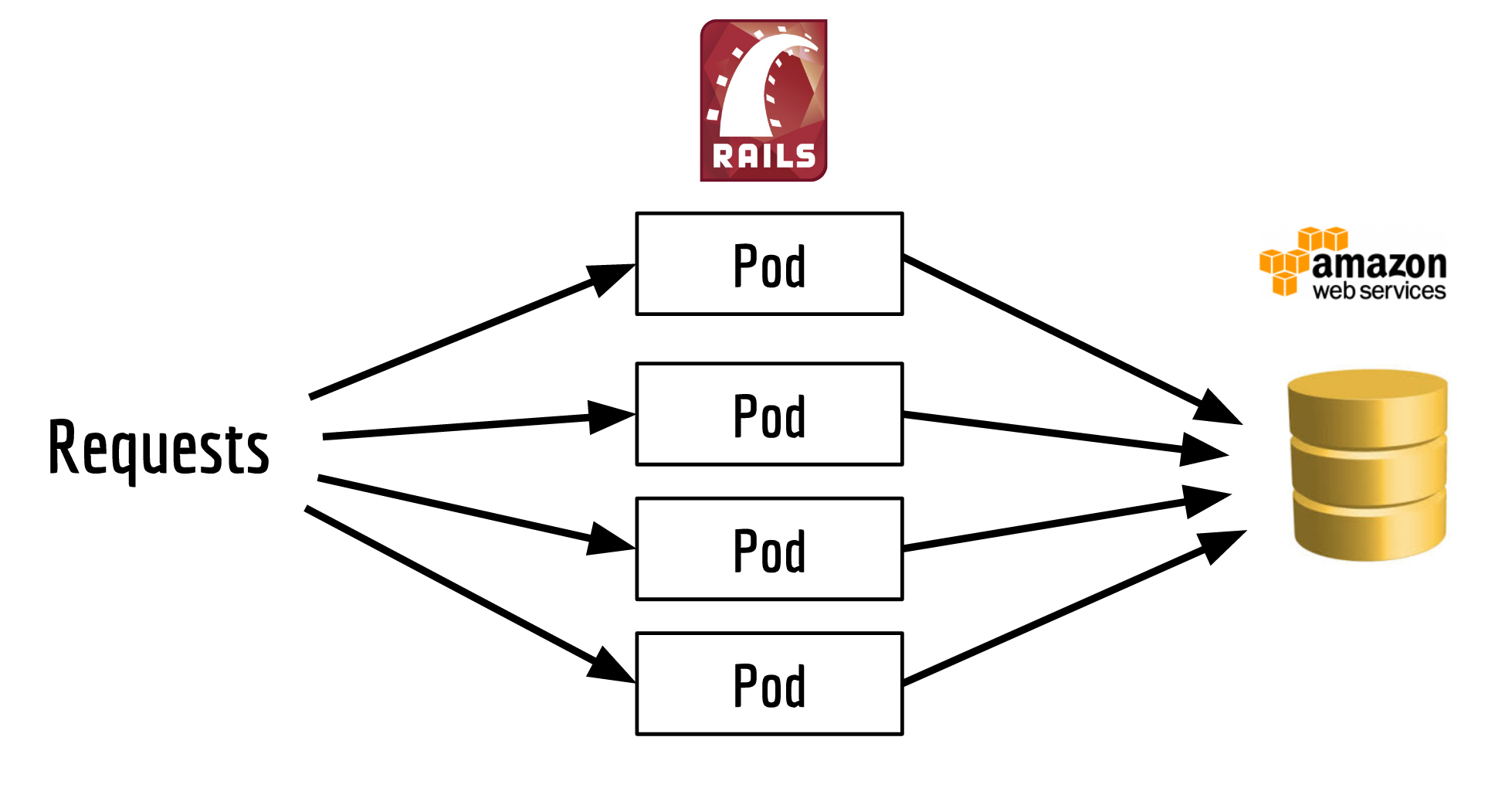
Each one of the pods is running an instance of our Ruby on Rails app.
Having read replicas for some of the database, exhausting read requests were on the top of our to-do list. More than 80% of requests that come to the backend are read requests, creating a sizeable target for a quick solution.
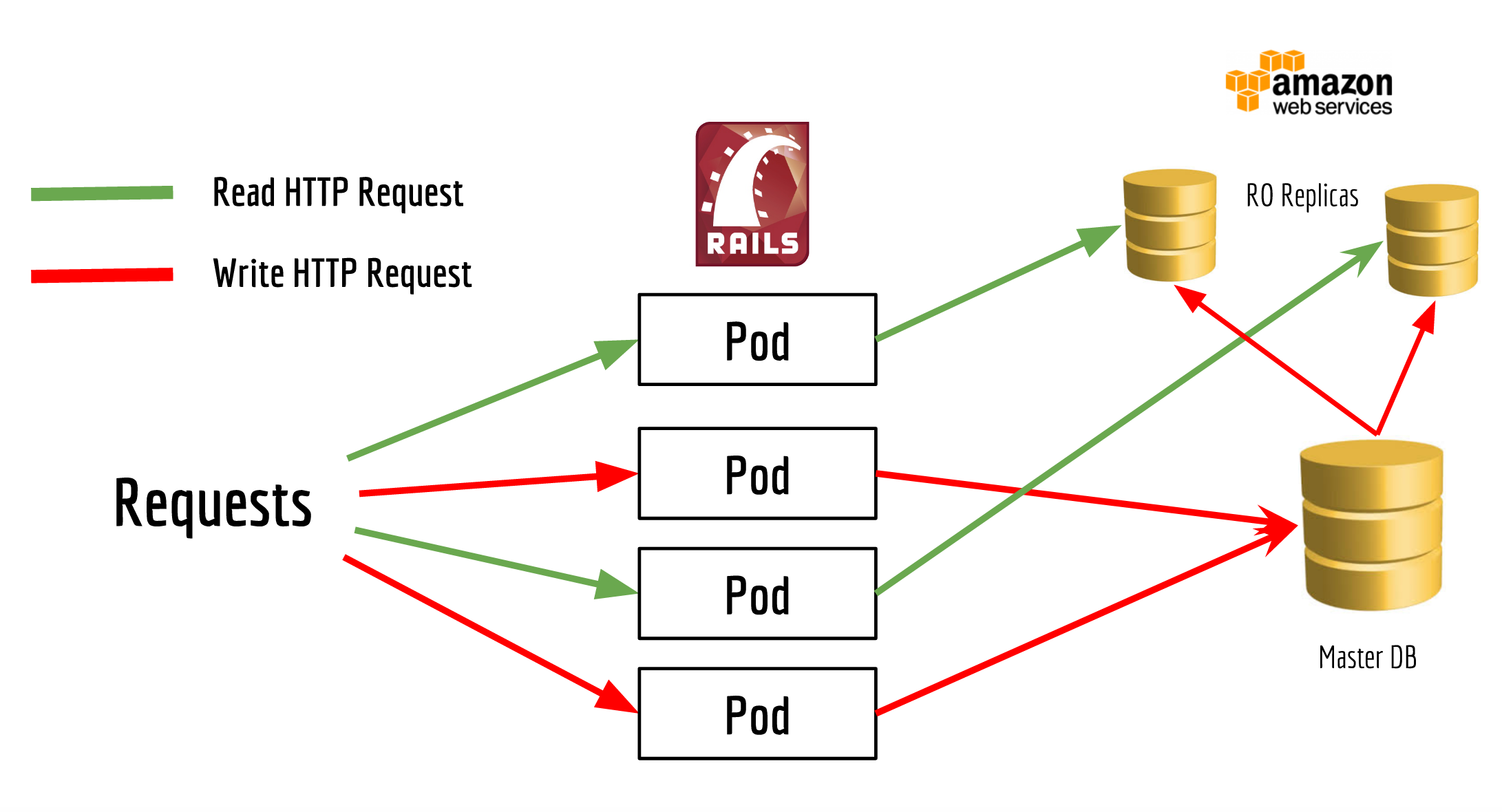
Our goal was to reach the architecture shown in this image, with as little effort as possible.
Setting up the Database Read Replicas on AWS
We pay a premium to use AWS RDS so we don’t have to concern ourselves with maintenance and configuring database servers. This means we create as many Read Replicas as we want for our Postgres database, simply by clicking a button and choosing the options that we want. Our only main constraint regards how much replication lag we can tolerate on our services, something I’ll outline shortly.
We discovered that the bigger the Replication Instances we create, the lower the lag. So we ended up having bigger instances that have around 0 seconds lag most of the time. But since this lag was something that we can’t guarantee all the time, we carefully selected the endpoints that we use to read from the Read Replicas.
The only downside we noticed was that AWS RDS doesn’t allow for the creation of Read Replicas from Read Replicas. Still, since we used only three Read Replicas, that wasn’t much of an overhead for our master database.
Preparing the Rails app to access the replicas
To make it easy for us to use Read Replicas in our Rails apps, we looked for out-of-the-box solutions, instead of reinventing the wheel with our own solutions. We found that one of the best ways to achieve that is by using the Octopus Gem.
We added it to the Gemfile like this:
gem "ar-octopus", ">= 0.9.0", git: "https://github.com/thiagopradi/octopus"We used a different fork, one that has support for Rails 5, and fixed some deprecation messages. If you want to use it with a Rails 4 app, then this should do the job:
gem "ar-octopus"For any normal Rails app, the standard config/database.yml config file would look like this:
development:
host: database_1_host
port: 5432
database: database
username: user
password: a_very_strong_passwordThis file will stay unchanged, and it will basically point to the master database. But
in order for Octopus to be configured with the list of data replicas, it needs to read
them from another separate file config/shards.yml. The absence of this file
means that replication is completely disabled, even if the Octopus Gem is installed.
Our config/shards.yml looks like this:
octopus:
replicated: true
fully_replicated: false
environments:
- production
production:
read_replica_1:
host: read_replica_1_host
port: 5432
database: database
username: user
password: a_very_strong_password
read_replica_2:
host: read_replica_2_host
port: 5432
database: database
username: user
password: a_very_strong_passwordSince Octopus gem supports sharding in addition to replication, the line
replicated: true
means: Octopus will assume all shards as slaves, and the database specified in database.yml as master database
And since we didn’t want all the Read Queries to be sent to the Read Replicas, we had to add the line
fully_replicated: false
But why don’t we send all the Read Queries to the Read Replicas?
Well, even though we rarely noticed any lag between the master database and the replicas, we wanted to avoid the case where a user updates their profile, but the updates are not reflected to their profile immediately. By comparison, the experience of finishing a workout and it is not appearing in the Feed right away isn’t a huge problem. That’s why we picked only the time-tolerant endpoints to read from the replicas, areas like the main Feed, leaderboard and the notifications tab.
The main Feed was our first experiment endpoint: since it’s requested a lot and it puts a lot of pressure on our master database.

Accessing the Replica with Octopus
So if not all the read database queries are sent to the replica database, then this means that you handle this manually. In Octopus, this can be done as easily as this:
Octopus.using(:read_replica_1) do
@user = User.find_by_email "some-random-email@example.com"
endSo you basically surround all the code you want with Octopus.using(:your_replica_name) {} block, and Octopus
will send any database queries inside that block to your replica instead of the master database.
But at Freeletics, since we created smaller database replicas db.r3.xlarge
than the db.r3.2xlarge master database, we also decided to route the Read Requests to the selected endpoints
as well as to the master database and the Read Replicas. For this to be achieved without having to hardcode and
replicate the database name in the code (like the snippet above),
we implemented this method DatabaseReplica.with_replication
class DatabaseReplica
def self.with_replication
if Octopus.enabled?
Octopus.using(available_databases.sample) do
yield
end
else
yield
end
end
def self.available_databases
read_replicas = Octopus.config[Rails.env].keys.map(&:to_sym)
@available_database ||= (read_replicas << :master)
end
endThis method basically takes the block that we were supposed to issue to Octopus.using(:replica_name) and sends
it against a random database (master or another other replica).
So with this, our Feed code would look like this
DatabaseReplica.with_replication do
# magic Rails code to read User Feed
render :index
endRemember to put the render statement inside that block, if you have any code that
triggers any queries in your views. For instance, the associations that are not included in your Relation before.
Was it really that easy?
No, not at all! Two years ago, when we managed to split our big monolithic bodyweight service into other small services, we made a hack that still exists in our code and production. Our bodyweight service still connects to the database of the new services directly, something we would have solved if we had more time.
We have Six ActiveRecord classes in our code that connect to the (Core User) service database. But Octopus isn’t aware of these cases. This means the ActiveRecord classes were actually trying to connect to the bodyweight database, instead of the core user database. See this class for example:
class CoreUser < ActiveRecord::Base
establish_connection :"core_user_database"
self.table_name = "users"
endWhen Octopus is enabled, CoreUser.last.destroy won’t touch the users table in the database core_user_database,
but instead it will try to delete the user from the bodyweight_database. Luckily for us, we
discovered this early when exceptions happened in loading the user, caused by the users tables and their different attributes.
So to make the long story short, it turned out that Octopus allows you to disable replication in some classes
by adding self.custom_octopus_connection = true to the class. So our CoreUser class ended up like this:
class CoreUser < ActiveRecord::Base
establish_connection :"another_database_for_users"
self.table_name = "users"
self.custom_octopus_connection = true
endWith that our problem was solved. Unfortunately the custom_octopus_connection wasn’t clearly documented
on the Github Octopus page, even if this Gem has a great documentation there. But we had to dig into the
source code to discover this solution.
OK, show me some results!
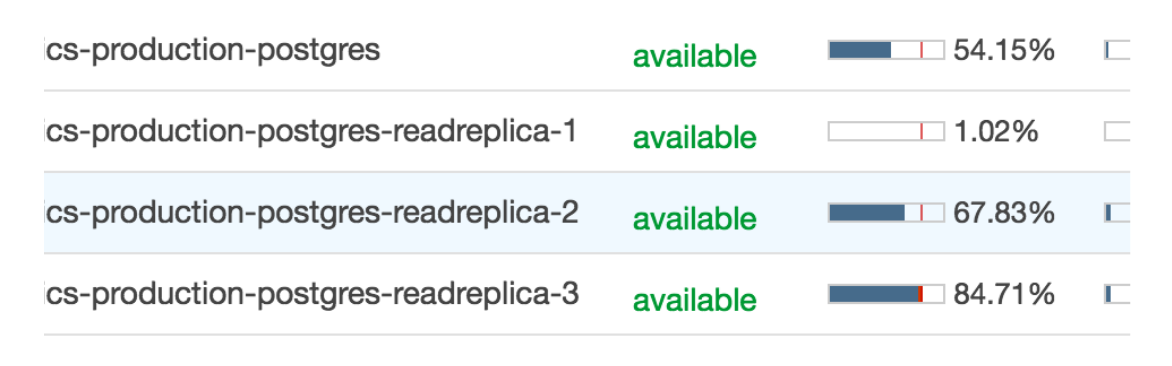
This image shows the CPU utilization of the main database alongside the replicas with high traffic simulated. Be aware that the first replica is not used for the app, but for internal use, which is why it is idle.
Summary
At Freeletics, we’re lucky to be working on some engaging topics that help millions of people enjoy their training, and improve their health and quality of life.