Fixing Flaky Tests in CircleCI

What should you do when your tests are failing and you don’t know why? You can either waste a few days trying to debug them, or read about it from someone who already has.
Anyone debugging their unit tests may find this article valuable, but it will be most relevant to you if you’re working with:
- CircleCI
- A Swift-based iOS project
- Unit testing for asynchronous cases (more on that later)
Let’s say that you’ve got a continuous integration (CI) system up and running, and for developers to merge their pull requests, they need all tests to pass on CI. This is standard practice, and one that we implement here at Freeletics. It’s great in theory, but once tests start to fail randomly, it becomes as useful as no tests at all.
Why? You have no idea whether a test failure is caused by critical code changes or an anomaly in the test bed environment! Even worse, your developers have to re-run CI jobs until they “get lucky” with a test that passes. When you are paying per-job using a service like CircleCI, these extra tests can add up to a considerable amount of money.
What it looks like
Shown below is a CircleCI job which experienced a “flaky failure.” Note that no tests are explicitly marked as failed, but rather, the job seems to fail in general.
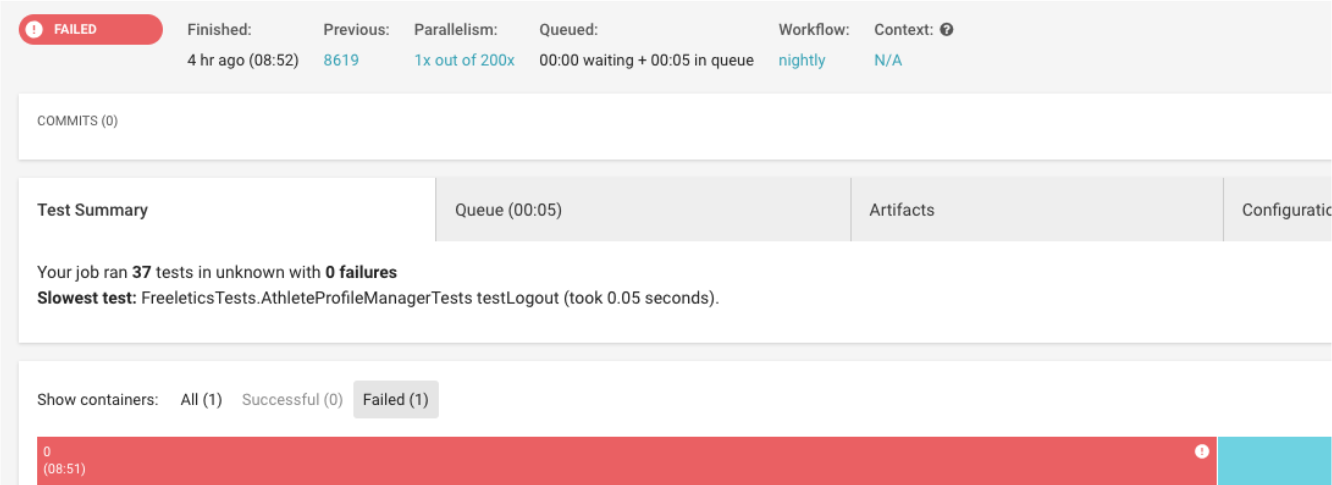
How do you debug something this cryptic? After some close examination of the logs, it appears that the iOS simulator has rebooted midway through the job. A quick way to find this is by searching for the word booted.
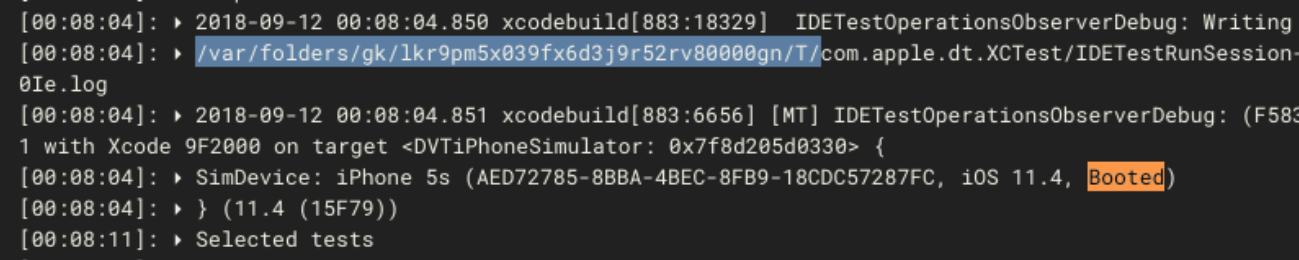
It’s normal for the simulator to boot before the tests begin, but a reboot midway through testing indicates that something went wrong.
Getting additional logs
To gain further insight, edit your CircleCI config.yml file to include additional logs. This will place the logs in the Artifacts tab after a job has finished. The logs we care about are in the directory highlighted above, something like /var/folders/gk/abcdefg123456/T/ (or whatever applies in your case). Thankfully, this random directory name stays the same between CI jobs.
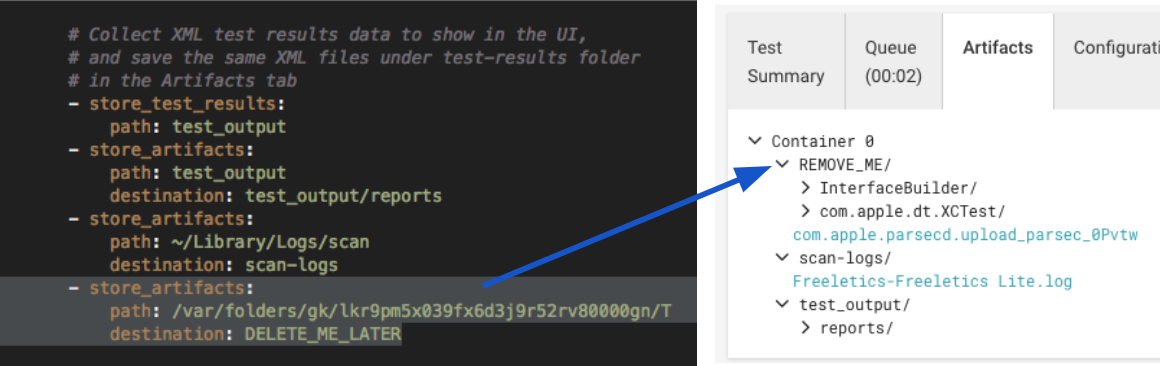
It’s a good idea to delete this additional logging after you’ve debugged your tests, as this directory can contain many large files and will increase memory/runtime used during testing.
Anyway, run more tests until you get another flaky failure, then check the additional logs. The directory structure should look something like this:
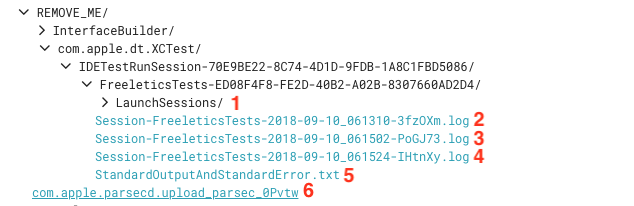
#1 and #6 are not very useful for our purposes. #2-5 are the most useful and contain logs from the simulator, i.e. the same output you would see if you ran these tests in Xcode.
Start looking through the logs and you will likely find an obvious test which caused the simulator to crash. You can identify this by searching for “error,” “failed,” “crash,” etc.

Above, I searched for “restart” and could quickly identify the problematic test: testCompactRounds in CompactWorkoutOverviewModelTest.
Fixing the flakiness
If only it were this easy…

In the case of our flaky tests, all of them shared a certain characteristic: using asynchronouos callbacks to fulfill test expectations. What this looks like in code is something like:
func testFoo() {
let expectation = XCTestExpectation(description: "foo")
DispatchQueue.main.asyncAfter(deadline: .now() + 100) {
expectation.fulfill()
}
wait(for: [expectation], timeout: 50)
}
There are two situations in which this type of test can cause a crash:
- Case 1: When the expectation is fulfilled more than once
- Case 2: When the expectation is fulfilled outside the lifecycle of the test
Case 1 is pretty straightforward. And if you are already setting expectation.expectedFulfillmentCount to be more than one, it won’t necessarily apply.
Case 2 is much harder to identify. Let’s walk through such a scenario:
- Create the expectation
- Fulfill it in a closure
- Wait for the expectation
- Waiting times out
- The test case function returns
- The closure is still called
- The expectation now points to a garbage memory address but is
fulfilled() - CRASH
So how do you fix it? Make the expectation weak!
This ensures that the expectation does not persist outside of the lifecycle of its test case. In code, this could look something like
func testBar() {
weak var expectation = self.expectation(description: "bar")
DispatchQueue.main.asyncAfter(deadline: .now() + 100) {
expectation?.fulfill()
}
waitForExpectations(timeout: 50, handler: nil)
}
Note that now we’re using self.expectation rather than XCTestExpectation. Is there any benefit to this? It’s tough to say. XCTestCase instances have an internal way of tracking outstanding expectations which have not been fulfilled, and using the instance method rather than the class method to create an expectation may be more stable.
Side note: If the callback is working on a background thread, fulfilling expectations in the main queue may also increase stability, i.e.
DispatchQueue.main.async { expectation?.fulfill() }
The benefit to using waitForExpectations(timeout:handler:) rather than wait(for:timeout:) is that we can avoid an extra if-statement:
func testBar() {
weak var expectation = self.expectation(description: "bar")
DispatchQueue.main.asyncAfter(deadline: .now() + 100) {
expectation?.fulfill()
}
// This is not ideal
if let expect = expectation {
wait(for: [expect], timeout: 50)
}
}
Another option is to simply make the expectation weak in the closure preface:
func testBar() {
let expectation = self.expectation(description: "bar")
DispatchQueue.main.asyncAfter(deadline: .now() + 100) { [weak expectation] in
expectation?.fulfill()
}
wait(for: [expectation], timeout: 50)
}
Happy testing!